This is from the Udemy course “Data Structures and Algorithms bootcamp”
You are given a string and you need to write code to tell whether the string is fully comprised of unique characters or not. You are given the following three unit tests:

I have three O(n) techniques:
- Use a hastable or hashset to determine whether or not the current character has already been added to the structure
- Similar to above: You don’t need a fancy data structure. You can simply use a primitive array, running from 0 to 25. Assuming you are using ASCII codes for the chars in your string, you can calculate where in the range 0,n,25 your char lies, and then add a bool or increment an int at that index. If this value is not 0/false, then this is not a unique char.
- You can use a bitmask. Complicated? Nope: same principle as the previous two. A normal 32 bit int has more than enough space for 25 characters. Hence, shift a ‘1’ by the chars range from 0,n,25, and (inclusive) OR it with the mask. If the value at this bit is already 1, then the character is not unique.
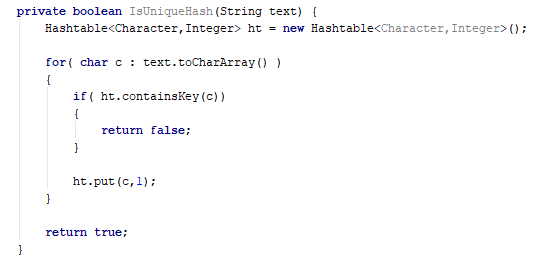

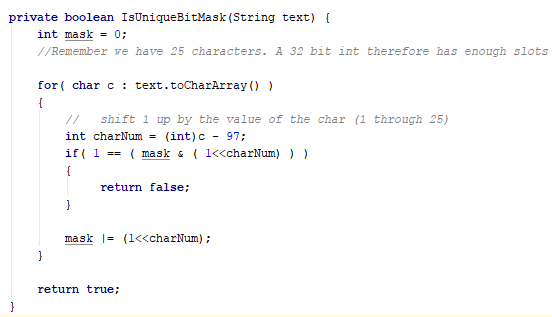
If you want to avoid using space, an O(n*n) technique for comparing every char with each other will work. Ensure to start the inner loop index (e.g., j) from the outer loop index (e.g., i) to not waste operations comparing chars you have already compared.